一:基础入门与算法分析
1. 核心概念
- 数据结构: 一门研究如何有效组织数据,以提高数据处理效率的学科。它关注数据间的逻辑关系(逻辑结构)和在计算机中的存储方式(存储形式)。
- 逻辑结构: 指数据元素之间的内在关系,与存储方式无关。常见有:
- 线性结构: 元素间为一对一关系 (如:线性表、栈、队列)。
- 非线性结构: 元素间为一对多或多对多关系 (如:树、图)。
- 存储形式 (物理结构): 指数据在内存中的存储方式。主要有:
- 顺序存储: 将逻辑上相邻的元素存储在物理位置也相邻的存储单元中(如:数组)。
- 链式存储: 物理位置不一定相邻,通过指针来表示元素间的逻辑关系(如:链表)。
[info] 核心思想
逻辑结构是“战略”,决定了数据应该如何组织;存储结构是“战术”,决定了数据具体如何存放。一种逻辑结构可以有多种存储实现。
2. 算法性能分析
算法分析旨在评估算法的优劣,主要考量两个维度:时间复杂度和空间复杂度。目标是让程序运行得更快,占用内存更少。
时间复杂度
概念: 衡量算法执行时间随数据规模增长而变化的趋势,通常不考察绝对时间,而是估算基本操作的执行次数(语句频度)。
表示法: 使用大O表示法
O(),只关注最高次幂项,忽略常数和低次幂项。(为什么只关注最大的?看这个视频:)
示例:
1
2
3
4
5
6
7
8
9void func(int n) {
// 执行 n 次
for (int i = 0; i < n; i++) {
// 执行 n*n 次
for (int j = 0; j < n; j++) {
printf("Hello\n");
}
}
}上述代码总执行次数为
n * n = n^2。因此,时间复杂度为 O(n²)。
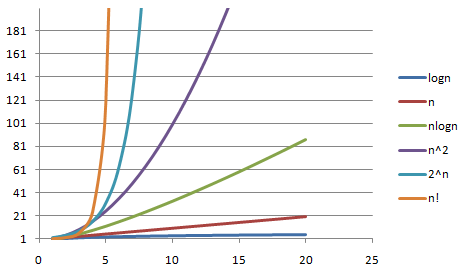
不同时间复杂度的增长趋势对比
空间复杂度
- 概念: 衡量算法在运行过程中临时占用存储空间大小的量度,同样采用大O表示法。
时空互换
概念: 在某些场景下,可以通过增加空间消耗来换取更短的执行时间(空间换时间),或者通过增加计算时间来减少内存占用(时间换空间)。
案例实战:快速计算二进制中1的位数
问题: 给定一个int,要求“尽快”求出其二进制表示中1的个数。
常规解法 (时间换空间): 循环移位或与操作,逐位判断。
1
2
3
4
5
6
7
8int count_ones(unsigned int n) {
int count = 0;
while (n > 0) {
n &= (n - 1); // 每次操作消除最右边的1
count++;
}
return count;
}高效解法 (空间换时间): 预计算。创建一个256大小的数组,存储0-255每个数包含的1的个数。对于32位整数,分4个字节查表相加即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14// 全局预计算表
int bits_in_char[256];
void precompute() {
for (int i = 0; i < 256; i++) {
bits_in_char[i] = (i & 1) + bits_in_char[i / 2];
}
}
int count_ones_fast(unsigned int n) {
return bits_in_char[n & 0xff] +
bits_in_char[(n >> 8) & 0xff] +
bits_in_char[(n >> 16) & 0xff] +
bits_in_char[(n >> 24) & 0xff];
}这是一种典型的用内存空间(
bits_in_char数组)换取固定时间(4次查表+3次加法)的策略。
二:线性表
线性表是数据结构世界的基础构件,其两种主要实现——顺序表和链表,在性能上各有取舍,适用于完全不同的场景。
3. 顺序表
- 定义: 使用一段连续的物理内存来存储逻辑上相邻的数据元素。在C语言中,其最直接的体现就是数组。
- 优点:
- 随机访问 O(1): 可通过下标直接访问任何元素,速度极快。
- 存储密度高: 无需额外空间存储元素间的关系。
- 缺点:
- 插入/删除 O(n): 在中间或头部操作,需要移动大量元素。
- 空间不灵活: 容量固定,扩容成本高或实现复杂。
- 适用场景: 数据量相对稳定,读操作远多于写操作的场景,如配置表、静态数据集等。
4. 链表
问题引入:为什么普通链表不够用?
我们先看一个普通的学生信息单链表节点:
1 | struct student { |
这个设计存在一个致命缺陷:缺乏通用性。next指针的类型是struct student *,这意味着为student链表编写的所有操作函数(如insert_student, remove_student),都无法用于管理teacher或其他任何类型的链表。在像Linux内核这样拥有成千上万种数据结构的复杂项目中,为每种结构都重写一套链表代码是不可接受的。
设计哲学:Linux内核的解决方案——数据与逻辑分离
Linux内核用一种极其巧妙的方式解决了这个问题:将**“链”的逻辑从“数据”本身**中抽离。
定义一个“纯粹”的链表节点: 创建一个不包含任何业务数据,只负责链接的通用节点结构
struct list_head。1
2
3
4// From <linux/list.h>
struct list_head {
struct list_head *next, *prev;
};这是一个标准的双向循环链表节点。
“寄生”于用户数据结构: 将这个
list_head结构作为一个成员,嵌入到任何需要被链式管理的用户数据结构中。1
2
3
4
5
6
7struct student {
// --- 用户数据域 ---
char name[20];
int id;
// --- 链表逻辑域 ---
struct list_head list; // "寄生"的内核链表节点
};
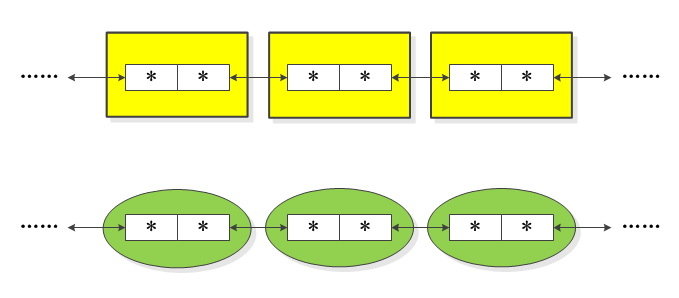
将标准链表节点嵌入用户数据结构
难点攻克:如何从“链”找到“数据”?
所有链表API操作的都是list_head指针,但我们最终需要的是包含业务数据的student结构体。如何从list成员的地址反向推算出其“宿主”student结构体的起始地址?
这就是内核链表最核心的宏 list_entry 的作用。
- 原理:
宿主结构体地址 = 成员地址 - 成员在宿主结构体中的偏移量
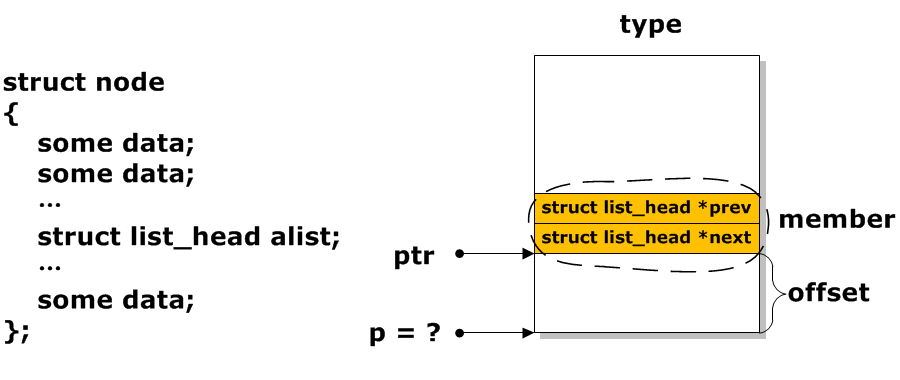
通过成员地址和偏移量计算宿主地址
C语言实现:
1
2ptr: 指向list_head成员的指针。type: 宿主结构体的类型 (如struct student)。member:list_head成员在宿主结构体中的名字 (如list)。&((type *)0)->member: 这是一个编译时技巧,计算出member在type结构体中的偏移量。
代码实战:使用内核链表管理学生信息
以下是一个完整的、可编译的示例,演示如何使用内核链表API。
(为方便使用,已将内核的list.h相关宏和函数提取整理)
kernel_list.h (简化版)
1 |
|
main.c
1 |
|
内核链表精髓总结
- 通用性: 一套API,管理所有类型的数据。
- 高效性: 增删操作为 O(1),无数据拷贝。
- 健壮性: 经过Linux内核数十年验证,稳定可靠。
- 思想: 完美的“控制反转”,用户只需关注自己的数据,将组织逻辑交给标准库。
代码实战:单链表的反转
掌握了链表的创建和遍历后,一个最经典的面试题和算法练习便是——反转一个单向链表。
例如,将 1 -> 2 -> 3 -> 4 -> 5 变为 5 -> 4 -> 3 -> 2 -> 1。
1. 核心挑战
在遍历链表时,每个节点只知道自己的“下一个”是谁。当我们想让 节点2 指向 节点1 时,一旦执行 2->next = 1,我们就会立即丢失通往 节点3 的路径。因此,算法设计的关键在于:在修改指针前,如何保存好“未来的路”。
2. 算法本质 - 三个职责的流转
无论代码怎么写,任何正确的迭代反转算法,都必须在循环的每一步中,清晰地管理好三个核心的“状态职责”:
Current(当前): 指向当前正要被反转指向的节点。Reversed(已反转): 指向已经反转好的新链表的头部。Upcoming(未反转): 指向Current在原始链表中的下一个节点,作为“路标”以防断链。
算法的每一步,就是这三个职责在指针变量之间的一次优雅“交谊舞”。
3. 思想的多种代码表达
表达一:标准三指针迭代法 (教科书式)
这是最常见、最清晰的实现。我们用三个独立的指针变量来分别扮演这三个角色。
p_rev: 扮演Reversed角色。p_cur: 扮演Current角色。p_upc: 扮演Upcoming角色。
1 | void reverse_list(linklist head) { |
深度思考:通过严谨的排列组合,我们可以证明,只要有三个指针变量,无论哪个变量扮演哪个角色(共 3! = 6 种组合),其核心的四步操作逻辑是完全一致的,都能写出正确的算法。
表达二:头插法 (巧妙利用头结点)
这种方法更加精炼,它巧妙地让“头结点”本身参与到算法中,扮演 Reversed 的角色。
p_cur: 扮演Current。p_upc: 扮演Upcoming。head->next: 扮演Reversed的角色,始终指向新链表的头。
1 | void reverse_list_head_insertion(linklist head) { |
表达三:递归法 (时空转换的艺术)
递归将迭代的循环逻辑转换为了函数调用栈的递进与回溯,代码极简,但对理解的要求更高。
- 递进 (Drill Down): 函数不断调用自身,直到链表末尾。这个过程本身就“记住”了返回的路径。
- 回溯 (Roll Back): 从链表末尾开始,在每一层函数返回时,将当前层的节点指针反转。
1 | // 辅助递归函数 |
思维体操总结
- 算法的“道”与“术”: 链表反转的“道”是管理好
Current,Reversed,Upcoming三个状态。而迭代法、头插法、递归法则是实现这个“道”的不同“术”。- 没有“碰巧”的正确: 即使写出一个非主流但可行的算法,也绝非巧合,而是无意中构建了一套逻辑自洽的状态流转系统。理解其内在逻辑,比死记标准答案更有价值。
- 代码是思想的投影: 同一个算法思想,可以有多种代码表达。探索这些不同表达方式的优劣和内在联系,是提升编程内功的关键。
代码实战:约瑟夫环
在掌握了链表的增删改查之后,约瑟夫环问题是另一个绝佳的综合性练习,它完美地融合了循环链表的构建与节点的规律性删除。
问题描述:n 个人(编号 1 到 n)围成一个圈。从第 1 个人开始报数,报到 m 的那个人出列,他的下一个人又从 1 开始报数,报到 m 的那个人再次出列……如此循环,直到所有人出列。请找出最后一个出列的人,或者按顺序输出出列人的序列。
为了解决这个问题,单向循环链表是天然的数据结构。
1. 算法分析与实现
约瑟夫环的核心操作只有两步,循环往复:
- “走”:从当前节点开始,向后移动
m-1步,找到那个“倒霉蛋”的前一个节点。 - “删”:将“倒霉蛋”从环中移除,并释放其内存。
算法持续进行,直到环中只剩下一个节点。
2. C语言代码实现
下面是一个完整的、可编译的约瑟夫环问题解决方案。程序会要求输入总人数 n 和报数阈值 m,然后模拟整个过程。
linklist.h (头文件)
1 |
|
main.c (主程序)
1 |
|
linklist.c (函数实现)
1 |
|
约瑟夫环问题总结
- 数据结构选择: 循环链表是该问题最直观、最自然的模型。
- 算法核心: 关键在于定位到待删除节点的前一个节点,这是安全删除链表节点的通用法则。
- 指针操作: 每次删除操作后,必须小心地更新当前指针(下一轮的起始点),确保逻辑链条不断裂。
- 边界情况: 考虑
n=1或m=1等特殊情况,能体现代码的健壮性。例如,当m=1时,每次都删除当前节点,指针移动的逻辑需要特别处理。
三:树形结构
二叉搜索树(BST)是利用树结构实现高效查找的典范。它的核心在于维持一个严格的有序性。
5. 二叉搜索树核心特性
- 定义: 对于树中任意节点,其左子树所有节点的值都小于该节点,其右子树所有节点的值都大于该节点。
- 价值: 平均情况下,查找、插入、删除操作的时间复杂度均为 O(log n),效率远超线性表的 O(n)。

6. 难点攻克:二叉树的删除操作
BST的插入相对简单,只需遵循规则找到空位即可。而删除操作则要复杂得多,因为它必须在删除节点后维持BST的有序性。
删除节点 x 的三种情况分析:
x是叶子节点: 最简单的情况,直接删除x,并将其父节点的相应指针置为NULL。x只有一个子节点 (左或右): 将x的父节点直接链接到x的唯一子节点上,然后释放x。x有两个子节点: 这是最复杂的情况。不能简单删除,否则会断开其两棵子树。- 解决策略: 在
x的子树中找到一个合适的“替身”来取代x的位置。这个替身有两个选择:- 前驱 (predecessor):
x左子树中的最大值。 - 后继 (successor):
x右子树中的最小值。
- 前驱 (predecessor):
- 操作步骤 (以后继为例):
a. 在x的右子树中,一路向左,找到最小值节点s(后继)。
b. 将s的值赋给x。
c. 问题转化为在x的右子树中删除节点s。由于s是最小值,它最多只有一个右孩子,问题降级为情况1或情况2。
- 解决策略: 在
图解删除双子节点 (删除节点 8)
假设我们要删除根节点 8:

1. 目标:删除节点 8。
a. 找到 8 的后继:在右子树 {10, 14, 13} 中找到最小值,即 10。

2. 找到后继节点 10。
b. 用后继 10 的值覆盖 8。

3. 用后继的值覆盖待删除节点。
c. 在原右子树中删除后继 10。此时 10 的删除操作属于情况2(它有一个右孩子 14),将其父节点(现在是新的根10)直接链接到其子节点 14。

4. 递归删除后继节点,完成重构。
代码实现:二叉树删除
1 | typedef struct node { |
[!WARNING] 二叉树的退化风险
如果插入的数据是预先有序或基本有序的,BST会退化成一个倾斜的链表,所有操作的性能将从 O(log n) 急剧下降到 O(n)。这正是**平衡二叉树(如AVL树、红黑树)**存在的意义。
四:栈与队列
栈和队列虽然在操作上受到限制,但正是这种限制赋予了它们独特的“先进后出”(LIFO)和“先进先出”(FIFO)特性,使其成为解决特定问题的强大工具。
7. 栈
- 核心特性: 后进先出 (Last-In, First-Out)。最后压入栈的元素,最先被弹出。
- 应用场景:
- 函数调用与递归: 这是栈最经典的应用。每次函数调用,其上下文(参数、返回地址、局部变量)被压入一个系统维护的“调用栈”。函数返回时,从栈顶弹出其上下文。递归本质上是函数调用自身的特例。
- 表达式求值: 将中缀表达式转换为后缀表达式(逆波兰表示法),然后使用栈进行求值。
- 括号匹配: 遍历字符串,遇到左括号就入栈,遇到右括号就检查栈顶是否为匹配的左括号,若是则出栈,否则不匹配。
- 深度优先搜索 (DFS): 在图或树的遍历中,DFS的递归实现天然利用了调用栈。其迭代实现则需要手动维护一个栈来存储待访问的节点。
实战案例:括号匹配
1 |
|
8. 队列 (Queue):FIFO的应用
- 核心特性: 先进先出 (First-In, First-Out)。最先进入队列的元素,最先被移出。
- 应用场景:
- 资源调度: 操作系统中的任务调度、打印机任务队列等,需要公平地处理请求,先到先服务。
- 广度优先搜索 (BFS): 在图或树的遍历中,BFS使用队列来存储待访问的节点,保证按层级顺序进行访问。
- 缓冲区 (Buffer): 在生产者-消费者模型中,队列作为缓冲区,平衡生产者和消费者之间速度不匹配的问题。
- 网络数据包排队: 路由器处理数据包时,通常将其放入队列中,按到达顺序转发。
实战案例:树的层序遍历 (BFS)
层序遍历是广度优先搜索在树上的直接应用,其核心就是队列。
1 | // 假设已存在BST的节点定义 bstNode 和一个简单的队列实现 |
五:排序算法
排序是计算机科学中最基础也最重要的操作之一。选择合适的排序算法对程序性能至关重要。
9. 快速排序
快速排序是实践中平均性能最好的排序算法,其精髓在于分治思想和高效的**分区(Partition)**操作。
难点攻克:partition函数的多种实现
partition函数的目标是:选择一个基准(pivot),并将数组划分为两部分,使得左边的都小于等于基准,右边的都大于等于基准,最后返回基准的最终位置。
实现一:Lomuto 分区方案 (易于理解)
- 思路:
- 选择最后一个元素作为
pivot。 - 维护一个指针
i,指向“小于等于pivot”区域的末尾。 - 遍历数组(除
pivot外),如果发现元素arr[j]小于等于pivot,则将i后移一位,并交换arr[i]和arr[j]。 - 最后,将
pivot(原arr[high])与arr[i+1]交换。
- 选择最后一个元素作为
1 | // Lomuto partition scheme |
实现二:Hoare 分区方案 (原始方案,效率更高)
- 思路:
- 选择第一个元素作为
pivot。 - 使用两个指针
i和j,分别从数组的两端向中间扫描。 i向右扫描,直到找到一个大于pivot的元素。j向左扫描,直到找到一个小于pivot的元素。- 交换
arr[i]和arr[j]。 - 重复3-5步,直到
i和j交错。
- 选择第一个元素作为
- 注意: Hoare方案最后返回的不一定是
pivot的最终位置,而是划分的分界点。
1 | // Hoare partition scheme |
完整的快速排序实现 (使用Lomuto)
1 | void quickSort(int arr[], int low, int high) { |
10. 归并排序
归并排序同样基于分治思想,但其核心操作是**归并(Merge)**而非分区。
- 核心思想:
- 分解 (Divide): 将数组递归地对半切分,直到每个子数组只有一个元素(天然有序)。
- 合并 (Conquer): 将相邻的两个有序子数组合并成一个更大的有序数组。
难点攻克:merge函数的实现
merge函数是归并排序的灵魂。它接收两个已排序的子数组,并将它们合并成一个单一的有序数组。
- 思路:
- 创建临时数组来存储合并后的结果。
- 使用三个指针,
i指向第一个子数组,j指向第二个子数组,k指向临时数组。 - 比较
arr[i]和arr[j],将较小的元素放入临时数组,并移动相应的指针。 - 重复此过程,直到一个子数组被完全处理。
- 将另一个子数组中剩余的元素全部复制到临时数组。
- 最后,将临时数组的内容复制回原数组。
代码实现:归并排序
1 | // Merge two subarrays of arr[]. |
| 特性对比 | 快速排序 | 归并排序 |
|---|---|---|
| 平均时间 | O(n log n) | O(n log n) |
| 最坏时间 | O(n²) (需要优化) | O(n log n) |
| 空间复杂度 | O(log n) (原地) | O(n) (需额外空间) |
| 稳定性 | 不稳定 | 稳定 |
| 适用场景 | 内部排序,对空间敏感 | 外部排序,对稳定性有要求 |
六:查找算法
查找(Search),是在数据集合中寻找特定元素的过程。看似简单的操作,在面对海量数据时,其效率直接决定了系统的响应速度和用户体验。不同的数据组织方式,催生了截然不同的查找策略。
12. 顺序查找:最朴素的策略
- 思想: 从数据集合的第一个元素开始,逐一向后比对,直到找到目标或遍历完所有元素。这是一种“地毯式搜索”。
- 时间复杂度: O(n)。在最坏情况下,需要检查集合中的每一个元素。
- 适用场景:
- 数据无序且无法排序: 当数据本身是杂乱无章的,且没有条件或必要去排序时,顺序查找是唯一的选择。
- 数据量极小: 当n非常小时,O(n)的开销可以忽略不计,简单的顺序查找因其实现简单而成为首选。
- 链式存储结构: 对于单向链表,由于其不支持随机访问,通常也只能采用顺序查找。
[info] 工程视角
不要轻视顺序查找。在很多嵌入式系统或对代码尺寸有严格要求的场景中,如果数据量可控,一个简单、无依赖的
for循环远比引入复杂的查找结构更具优势。“简单”本身就是一种强大的工程美学。
13. 二分查找 (Binary Search):有序世界的利器
当数据集合有序且支持随机访问(如数组)时,二分查找展现出惊人的威力。
- 思想: 通过不断将搜索区间折半,以对数级的速度逼近目标。每比较一次,就能排除掉一半的不可能选项。

二分查找动态过程
- 时间复杂度: O(log n)。对于100万个数据,最多只需20次比较;对于10亿个数据,也仅需约30次。
难点攻克:二分查找的“魔鬼细节”与鲁棒实现
二分查找的原理简单,但完美实现却充满陷阱。高德纳(Donald Knuth)曾说:“虽然二分查找的基本思想相对简单,但细节可以非常棘手……第一个正确的二分查找算法在1946年就已出现,但第一个没有错误的实现直到1962年才发表。”
常见的陷阱:
- 整数溢出: 计算中点时,
mid = (low + high) / 2在low和high都很大时可能导致它们的和溢出。 - 死循环: 当区间更新逻辑不当时(如
low = mid或high = mid),在特定边界条件下可能导致搜索区间无法缩小,陷入死循环。 - 边界条件处理: 循环的终止条件是
low < high还是low <= high?区间更新是high = mid还是high = mid - 1?这些微小的差异决定了算法的正确性。
实战代码:一个健壮的二分查找模板
这个模板通过精巧的边界设计,可以清晰地处理“查找特定值”、“查找第一个大于/等于某值的位置”等多种变体。
1 |
|
[info] 模板分析
- 循环条件
low <= high: 保证了当搜索区间缩至单个元素时,该元素仍能被检查。- 区间更新
low = mid + 1和high = mid - 1: 确保每次循环都至少排除mid本身,从而保证了区间的严格缩小,避免死循环。
14. 分块查找:空间换时间的折中艺术
在无法对全部数据进行完全排序,但可以进行宏观分组的场景下,分块查找提供了一种优雅的性能提升方案。
- 思想: 分块 + 索引。将大数据集分割成若干“块”,为这些块建立一个“索引表”。
 ➡️
➡️ 
从字典的部首检字法到分块查找
结构:
- 数据块: 原始数据被划分为连续的块。块内元素可以无序,但块间必须有序(例如,第 i+1 块的所有元素都大于第 i 块的所有元素)。
- 索引表: 一个小数组,每个条目对应一个数据块,存储该块的关键信息(通常是块内最大值)和起始地址/索引。
查找过程:
- 第一步:在索引表中查找。由于索引表本身是有序且数据量小,可以使用二分查找(或顺序查找)快速定位目标值可能所在的块。
- 第二步:在数据块内查找。进入定位到的数据块,在块内进行顺序查找。
性能分析: 设数据总量为
n,分为b块,则每块大小为n/b。索引查找时间为O(log b)(用二分法),块内查找时间为O(n/b)。总时间复杂度为 O(log b + n/b)。通过调整块的数量b,可以在时间和空间(索引表大小)之间找到平衡点。当b = sqrt(n)时,可以取得较好的理论性能。
工程价值与适用场景
分块查找的真正价值在于它对数据容忍了一定程度的无序,非常适合处理动态变化的数据集。
- 场景: 数据库索引。数据库的表数据在物理上可能不是完全有序的(因为增删改),但数据库会维护一个B+树索引(一种高级的多路分块结构)。查找时,先通过索引快速定位到包含目标数据的数据页(块),然后再在数据页内查找。这使得在海量动态数据中进行高效查找成为可能。
- 优点: 在插入新数据时,只需找到对应的块并插入,无需像维护一个完全有序数组那样移动大量数据。它在查找效率和维护成本之间取得了出色的平衡。
15. 哈希查找 :O(1) 的理想与现实
前面所有查找算法,都离不开“比较”。而哈希查找另辟蹊径,试图通过一次计算就直接定位到数据。
思想:
- 哈希函数 (Hash Function): 设计一个函数
h(key),它能将任意的关键字key映射到一个固定范围的整数,这个整数就是数据在哈希表(通常是一个数组)中的存储位置(索引)。 - 哈希表 (Hash Table): 一个数组,用于存储数据。
- 查找: 当要查找一个
key时,只需计算index = h(key),然后直接访问哈希表的index位置即可。
- 哈希函数 (Hash Function): 设计一个函数
时间复杂度: 理想情况下,每次查找只需一次哈希计算和一次数组访问,时间复杂度为 O(1)。
难点攻克:哈希冲突
理想是丰满的,现实是骨感的。不同的key通过哈希函数可能会计算出相同的index,这就是哈希冲突。
- 例子:
h(key) = key % 10。h(12)和h(22)都会得到索引2。
解决冲突的常用方法:
- 开放定址法 (Open Addressing): 如果计算出的位置已被占用,就按照某种规则(线性探测、二次探测等)去寻找下一个空位。
- 链地址法 (Chaining): (最常用)哈希表的每个位置不再是单个元素,而是一个链表的头指针。所有哈希到同一位置的元素,都以节点的形式挂载到这个链表上。查找时,先计算哈希值定位到链表,再在链表上进行顺序查找。

链地址法解决哈希冲突
性能总结与对比
| 查找算法 | 数据要求 | 平均时间复杂度 | 最坏时间复杂度 | 空间复杂度 |
|---|---|---|---|---|
| 顺序查找 | 无 | O(n) | O(n) | O(1) |
| 二分查找 | 有序, 随机访问 | O(log n) | O(log n) | O(1) |
| 分块查找 | 块间有序 | O(log b + n/b) | O(log b + n/b) | O(b) |
| 哈希查找 | 无 | O(1) | O(n) (全冲突) | O(n) |
最终洞察:
- 没有最好的算法,只有最合适的算法。
- 二分查找是静态有序数据集的王者。
- 哈希查找是追求极致查询速度(尤其是动态数据集)的首选,但以额外的空间和哈希函数设计为代价。
- 分块查找和其衍生(如B树)是在查找效率和动态维护成本之间寻求平衡的工程典范,是大型数据库和文件系统的基石。



